The following is data is all at 4-on-5 with both goalies in their nets. A special thanks to Evolving Hockey for data and their scraper.
In March of 2019, Mike Pfeil coined the term “powerkill” at the Seattle Hockey Analytics Conference. It was much more of a small excerpt from his whole presentation, but it seemed to motivate Meghan Hall and Alison Lukan. In the coming months, Lukan would write about how the Columbus Blue Jackets utilized an aggressive approach in their penalty killing system, while Hall would present at RITSAC and OTTHAC before they finally came together to present at the Columbus Blue Jackets Hockey Analytics Conference in February.
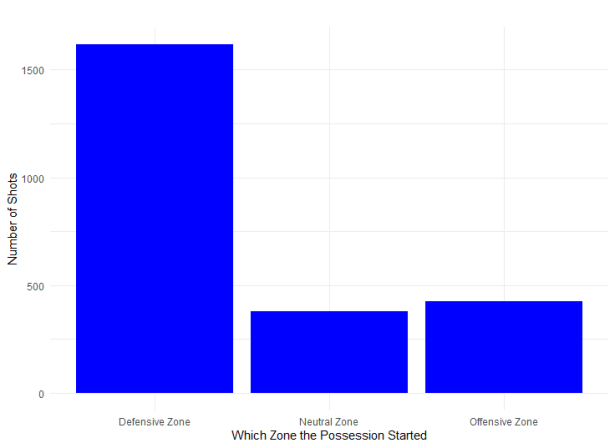
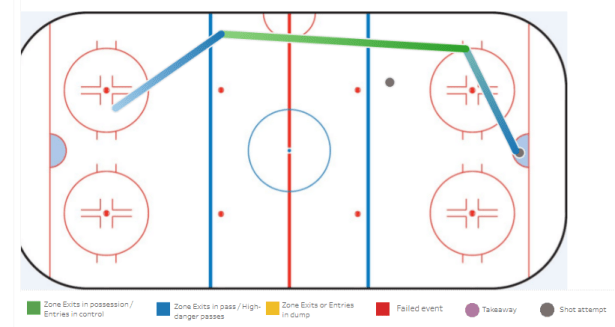
Looking to continue researching this phenomenon, I set out to answer a few questions I had. In order to give shots some added context beyond what the NHL’s public data supplies, throughout the last few months, I tracked shot assists and where possessions leading to shots had started. As a side benefit, I was also able to filter out shots that didn’t appear to exist, were recorded incorrectly, or where the possession started at 4-on-4.
In 2016, Matt Cane developed a metric to approximate penalty kill aggressiveness by combining penalty kill controlled and failed entries for, and dividing them by the entries a penalty kill faces from their opponent. The theory behind that being that penalty kills that attempt to control more entries into the offensive zone are inherently more aggressive. Hall and Lukan also found that a penalty kill’s rate of controlled entries has a strong correlation to the rate at which they take shots.
Part of the reason these two stats have such a strong correlation is that the vast majority of shots require a zone entry. Not including rebound shots, 82% of 4v5 shots stemmed from possessions starting outside of the offensive zone over the course of the 2019-20 season.