Every once-in-a-while I will rant on the concepts and ideas behind what numbers suggest in a series called Behind the Numbers, as a tip of the hat to the website that brought me into hockey analytics: Behind the Net. My ramblings will look at the theory and philosophy behind analytics and their applications given what is already publicly known.
Hello everyone; I am back! I was in the process of writing an article on NHL prospect development for after the draft (teaser!) when a Twitter thread sparked my interest and made me want to do a bit of a ranty, very pseudo-Editorial or Literature Review on analytics and the draft while combing over that thread.
As a scout who is a huge proponent of the use of analytics in pro and amateur player evaluation, i find it very interesting that many of the same people who dive into NHL advanced stats and create/support models are huge supporters of NHLe in prospect evaluation 🧵(1/10)
Cowritten by Brendan Kumagai, Mikael Nahabedian, Thibaud Châtel, and Tyrel Stokes
This is part 2 of a two part series introducing our Bayesian space-time model for evaluating offensive sequences and player actions. In part 1, we outlined our methodology to build the model and explained the reasoning behind the key metric, Possession Added Value (PAV), derived from it. In this second part, we will illustrate how our model and the PAV metric can be used for team and individual player analysis. Read Part 1 here.
Introduction
Since the Big Data Cup in March, our team has continued to improve the model to better estimate Possession Added Value of offensive sequences. With some extra time on our hands we cleaned up a few coding bugs and made two changes to the underlying models themselves. First, we have explicitly separated failed and completed passes. Second, we drastically improved our models which predict the location of the next event. With these changes we are able to more realistically simulate play sequences and more accurately value passing and as a result the findings presented below might differ a bit from our Big Data Cup paper.
It’s not easy creating a data-driven decision-making culture in any organization, let alone one as bound in tradition and lore as the NHL, where hockey men are imbued with mythical powers of observation and judgement just by virtue of having played the game. And yet, the NHL is clearly moving in that direction. It may be at a glacier-like pace, but I suppose that makes sense, what with the ice and all. Despite some early stumbles, it’s probably safe to say that it is only a matter of time before data-driven decisions are the norm rather than the exception. Whether that happens while we still have glaciers is another matter.
But even when there is a managerial will and top-down direction to move toward a data-driven culture, it is often difficult to introduce data analysis into the existing decision-making process of an organization. It’s not just deep structural changes that are necessary, but also staff will need a robust change management process. It’s hard enough to get people to accept change, but a new culture requires that they go beyond acceptance and embrace it as a new way of doing things. This is a difficult process in any organization. However, it is made more difficult in the hockey world where many in positions of authority are in those roles precisely because they “played the game” and understand the traditional way of doing things.
But what if you could start from scratch and build something from the ground up?
Cowritten by Brendan Kumagai, Mikael Nahabedian, Thibaud Châtel, and Tyrel Stokes
Introduction
This is part one of a two part series introducing our bayesian space-time model for evaluating offensive sequences and player actions. In this part we describe the model and the key metrics derived from it. In part 2 we will show how the model can inform and integrate with player and team evaluations.
Hockey is a game of making the best possible decision in the shortest amount of time. Players need to react quickly to form a chain of plays to create valuable scoring chances. Our goal is to quantify the value of player actions as a function primarily of space and time in the offensive zone. This is to recognize that the puck location and the threat-level it poses to the opposition is a key driver of what options will be available to the puck carrier and – as a result – what is likely to happen next. Ultimately, we want to credit players that are able to make high quality decisions and difficult plays which advance the puck into more valuable locations on the ice.
To this end, we primarily build off of 3 previous papers. First, we use the conceptual framework of understanding play sequences in hockey (Châtel, 2020) from our team member Thibaud Châtel. Second, we adapt the multi-resolutional Expected Possession Value modelling framework pioneered by Cervone et al. (2016) in basketball to work with the detailed play-by-play data generously provided by Stathletes as part of the Big Data Cup hackathon. Finally, using this infrastructure we propose a metric called the Possession Added Value (PAV) based on Karun Singh’s Expected Threat Model in soccer (Singh, 2018) which has previously been adapted to hockey (Yu et al., 2020).
Due to the timeframe of the competition and the complexity of our proposed model, we decided to narrow our scope down to offensive even strength sequences that begin with an entry and end with either a shot or a whistle. By only considering offensive sequences the model as it stands can only properly evaluate the actions of the offensive team.
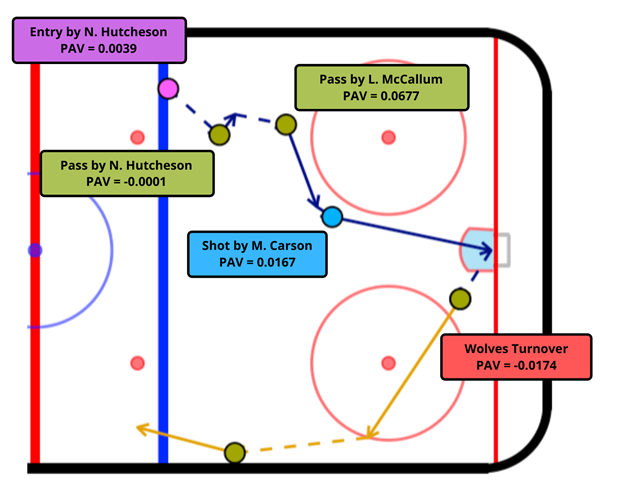
Before we dig into our methodology, here is an example of what our end product will look like in Figure 1 below. We assign each event in this entry-to-exit/whistle sequence with our Possession Added Value (PAV) metric, which can be thought of as the increase in probability that we score in the sequence by performing the observed action. For example, the pass by Landon McCallum from the top of the left circle into the slot adds 0.0677 goals to the expected value of the possession.
Figure 1: An offensive zone sequence with our Possession Added Value (PAV) metric
This was co-written by Mike Murphy, Alyssa Longmuir, and Shayna Goldman based on work for the Big Data Cup and Ottawa Hockey Analytics Conference.
As a result of women’s hockey analytics needing to play “catch up,” it’s not unusual to see analysts relying on stats that have already been proven to be less insightful in the men’s game. One such area of the game that is frequently highlighted at the collegiate, professional, and international levels of the women’s game are faceoffs.
Faceoffs have been covered extensively in men’s hockey, and much of that work points to the fact that faceoffs wins aren’t all that they’re chalked up to be. Back in 2015, Arik Parnass, now of the Colorado Avalanche, found, “This … aligns with what hockey analysis has found over the years when it comes to faceoffs. Overall, winning them just isn’t as important as it’s made out to be.”
While a great deal of work has been done on the importance (or lack thereof) of faceoffs in the men’s game the same cannot be said of women’s hockey. But why would it be any different?
Every once-in-a-while I will rant on the concepts and ideas behind what numbers suggest in a series called Behind the Numbers, as a tip of the hat to the website that brought me into hockey analytics: Behind the Net. My ramblings will look at the theory and philosophy behind analytics and their applications given what is already publicly known, keeping my job safe while still getting to interact with the public hockey-sphere.
Hello. Hope everyone is enjoying my return after a long hiatus. I am back from my busy schedule of helping run a tracking company that sells private tracking data to argue here against overvaluing private tracking data (and in addition black-box models)… or really I’m suggesting to not underrate what’s in the public.
You heard that right. The guy that has vested interests in demonizing public models and data is going to defend public models and data!
We’re bringing it back! Every once in a while I will rant on the concepts and ideas behind what numbers suggest in a series called Behind the Numbers, as a tip of the hat to the website that brought me into hockey analytics: Behind the Net. My ramblings will look at the theory and philosophy behind analytics and their applications given what is already publicly known, keeping my job safe while still getting to interact with the public hockeysphere.
I’m back and here to ramble on things like models, sheltering, and environmental impacts on the results we measure.
The recently agreed CBA extension and MOU (April 2020) includes provisions suggesting a flat salary cap for years to come, and as a result, general managers and players have experienced an unprecedented draft, free agency and arbitration marketplace this fall. NHL league activity is expected to continue under a particularly unique context caused by loss of hockey related revenue from the Covid-19 pandemic, and the upcoming Seattle expansion draft.
Under this challenging and uncertain financial landscape, I endeavored to conduct contract research to better identify league-wide contract negotiation trends and evaluate anticipated flexibility of NHL team’s salary cap structures by looking at: – No-trade clauses – Signing bonuses (S.B.) – Injury reserve (IR) and long term injury reserve (LTIR)
While the 2022 Beijing Winter Olympics are still over a year away and the memories of Pyeongchang are still fresh in many fans’ minds (with only one World Championship taking place since then) centralisation for both Canada and the USA is rapidly approaching. Countries historically pick their rosters around late May, beginning of June in the year prior to the Olympics to allow time for players to train, bond and participate in exhibition games before the final roster selection occurring just a month before the big event. What goes on during those 9 months prior to skating out of that Olympic ice surface is largely kept a secret with roster decisions often being announced in a somewhat cut-throat manner and additional players often being drawn in from outside the bubble to the surprise of everyone. Throughout this article, we will be looking at the survival rates of skaters on National Teams over the past 30 years and investigating what this means for roster selection heading into Beijing.
In 2018 between the two teams there were only 3 first time players. Cayla Barnes and Sidney Morin both lined up for the USA on the big stage while Sarah Nurse did the same for Canada. That is of course not to say these players didn’t have prior international experience. Nurse made her national team debut at the 2015 4 Nations Cup and had also represented Canada at a U18 level. Cayla Barnes while just 18 at the time of centralisation had played for the United States 3 times at U18’s including Captaining them to a Gold medal that very year while Morin had previously represented the USA at the 2017 The Time Is Now Tour. While there were only 3 ‘true’ rookies between the two teams that was not to say this was the same line-up as the previous Olympic in Sochi with Team Canada having 8 players missing from their gold medal-winning Sochi side, and the USA missing 7. I have put their names below as we will return to them later.
CANADA
USA
Caroline Ouellette
Alex Carpenter
Catherine Ward
Anne Schleper
Gillian Apps
Josephine Pucci
Hayley Wickenheiser
Julie Chu
Jayna Hefford
Kelli Stack
Jennifer Wakefield
Lyndsey Fry
Lauriane Rougeau
Michelle Picard
Tara Watchorn
Skaters from the 2014 rosters not included in the 2018 rosters
For me at least, hand tracking is 99% of the time born out of necessity.
The only way I am ever going to get location data for shots is if I break out a multicoloured pen and write down all the locations and numbers myself. Its isn’t however exactly the quickest process to deal with.
I actually really enjoy hand tracking is the thing, It keeps me focused on the game at hand and stops my mind from wandering. The issue comes when it’s time to digitise that information for analysis. I have written about this before over at The Ice Garden, back when I tracked an entire season of the Australian Womens Hockey League. That season it took me around an hour of straight work to plug in every piece of information so that tableau could process it and as my life got busier, the amount of free time I could dedicate got less and less.
The idea to force a shiny app to do something it has no right to do came out of necessity. Partially because I wanted to be able to show heat maps to the Head Coach of the local team I work with during intermission, but mostly because my Masters project consists of getting school kids ages 11+ involved in sports analytics and I really wanted them to be able to produce their own heat maps and yet I really did not want to attempt to explain the complexities of Kernel Density Charts to a collection of 12-year-olds.