Continued from Pt. 1
When do women’s hockey players reach their peak? How do they develop? These questions may sound straightforward, but they are exceedingly difficult to answer because of the finite opportunities for players to pursue high-level post-collegiate hockey. There is no consensus “top” professional league in the world, and major international tournaments are brief; conclusions we draw from them can be heavily skewed by the group format.
For all these reasons and more, NCAA DI (Division I) is a logical place to explore player development. It is data-rich, relative to the rest of women’s hockey, and Carleen Markey’s work with aging curves placed CWHL (Canadian Women’s Hockey League) skaters’ peak offensive production between the ages of 22 and 23. That falls within the range of many collegiate careers.
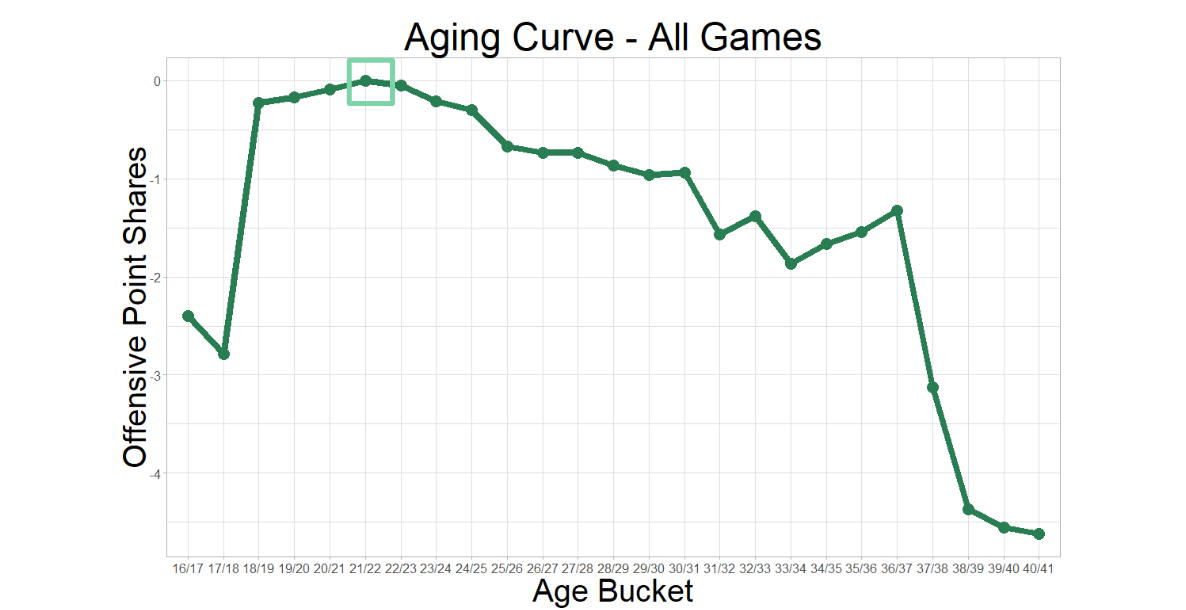
Credit: Carleen Markey
The Pipeline
The zenith of skill and competition in the world of women’s hockey are the Olympics and the IIHF Women’s World Championship. These tournaments are filled with, and often dominated by, active DI players and alumnae. As one might expect, the majority of those players represent Team USA and Team Canada.
At the 2019 Worlds in Espoo, Finland, all of Team USA’s roster and 20 of the 23 players on Team Canada spent at least one year in an NCAA DI program, compared to just five of the 23 players on Team Finland’s silver medal-winning team, and one player on Team Russia’s fourth-place team.
That said, there are more international players playing college hockey in North America every year. Per biographical data on EliteProspects.com, the ratio of international players in DI hockey climbed from 4.17 percent in 2015-16 to 5.07 percent in 2019-20.
Those percentages don’t mean much without the context of the women’s hockey landscape across the globe. According to the IIHF, there are 88,732 registered female players in Canada and 82,808 in the U.S. Outside of North America, there are 26,381 registered players in Sweden, Finland, Czech Republic, Russia, France, Germany, Switzerland, Japan, and Norway combined.
Continue reading →