
The NHL Draft acts as the proverbial reset of the NHL calendar. Teams re-evaluate the direction of their organizations, make roster decisions, and welcome a new crop of drafted prospect into the fold. Irrespective of pick position, each team’s goal is to select players most likely to play in the NHL and to sustain success. Most players arrive to the NHL in their early 20s, which leaves teams having to interpolate what a player will be 4-5 years out. This project attempts to address this difficult task of non-linear player projections. The goal is to build a model for NHL success/value using a player’s development — specifically using all current/historical scoring data to estimate the performance of a player in subsequent seasons and the possible leagues the player is expected to be in.
Past Work
A project like this is only possible by virtue of the hard work that came before it. Many of the core principles have been unchanged, such as NHL value, probability of success and league conversion.
The list of prospect models is long, comprehensive, and dates back to hockey analytics’ infancy. The work of APPLE’s predecessors/inspirations:
- PCS (Lawrence, Weissbock)
- SEAL (Hohl)
- pGPS (Davies)
- DEV (Speak)
- Model Trees for Identifying Exceptional Players in the NHL Draft (Schulte, Liu, Li)
- NHLe (Desjardins / Vollman / Tulsky / Perry / Bader)
- NNHLe (Turtoro)
Much of the focus on NHL Draft / Prospect work concentrates on the following objectives (and are not mutually exclusive in application):
- Scoring Translations
- Player Comparables
- Optimal Draft Value
In my view, these are the foundational concepts and questions that hockey analysts set out to tackle when it comes to prospects. APPLE is no different — the goal is to expand on the work that’s come before, and offer a different approach that address potential shortcomings like:
- Time dependence (Age, inter-season correlations)
- Selection bias (using only players that appear in multiple leagues in the same season)
- Arbitrary response variable (ie. 200 NHL game cutoff)
APPLE draws on the same principles of PCS/DEV in the sense that it is trying to (1) capture the inherent risk / reward of each player’s development and (2) avoid selecting clusters of players or fitting on an arbitrary target variable that defines “NHL success”. We’re also drawing from concepts of NHLe/NNHLe in that we’re trying to estimate league equivalencies of production, albeit in season y+1 not in season y. Lastly, we’re instead modeling time dependence as part of the model architecture instead of simply treating each player season independent of past performance — Cody Glass won’t wake up one tomorrow looking like Nathan MacKinnon or Ryan Reeves; he will most likely be closer to a prior (himself).
Methodology
I wrote about a prospect model last year, with the introduction of the Probability Peers prospects model (PPer). Unlike other prospect success models pGPS/PCS, the PPer was a regression model. PPer was most similar to DEV in that it was a binary classification fit on NHL Success (200 GP), with clusters fit using K-means on height/weight/probability of success to derive player comparables. In the end, I came away still feeling unsatisfied having not really addressed the obvious issues of (1) an arbitrary response variable (200 GP cutoff for measure of “NHL success”) and (2) violating a key assumption of linear regression because each player season is not independent. A few weeks later after I published PPer, my friend Nicole Fitzgerald (Microsoft, soon to be MILA institute), who works in ML research, proposed these concerns could be addressed as a Long Short-Term Memory (LSTM) time series problem.
That got me thinking.
Most time series problems using neural networks, specifically the recurrent neural network (RNN) architecture, leverages deep learning frameworks like LSTM to encode historic information about the sequence to aid prediction. Many tutorial examples using open-source machine learning libraries (such as PyTorch/Keras) are based on Stock Price prediction. Hockey players are viewed as assets for their organizations, so I thought the analogy was close enough.
The LSTM architecture, put simply, uses sequential data to updates cell states, hidden states, and produces an output. That output is the prediction for that time-step and will be compared against the ground truth in training. The cell and hidden states are updated as sequential data is passed through the network.

The analogous hockey use-case is to treat each player as a sequence that begins when they’re 17 and ends when they’re 23. I chose this time window because these are usually the development years for players. This time window also roughly coincides with when an NHL team has drafting rights on a player. Each player is initialized with the same hidden, cell state when we begin at year y. Then, we iteratively pass input data about the player’s league, performance, measurements and other player features. The model produces an output for each time-step, i.e. player performance in y+1.
What this allows us to accomplish is predict any future player performance entirely by past performance history. The goal is for the LSTM architecture to capture the time-dependent, complex non-linear patterns as players develop, and to trace their path to the NHL.
This is far and away the biggest philosophical change to APPLE when trying to evaluate player development — treating time as a meaningful dimension in the problem. Not only is player age important in player development, but there are implications on salary cap and asset management as soon as a player is drafted. Evaluating a prospect / pick is a careful balance between risk and reward, much like trading stocks. The goal is to model both risk and reward components separately and to bring it all together at the end to give us an expected NHL value up until when teams loses entry-level contract rights. APPLE is composed of 3 main models. We use a similar set of player features as the PPer:
- Predict what league player plays in y+1
- Predict player scoring conditioned on the league in y+1
- Impute remaining features
Data Processing
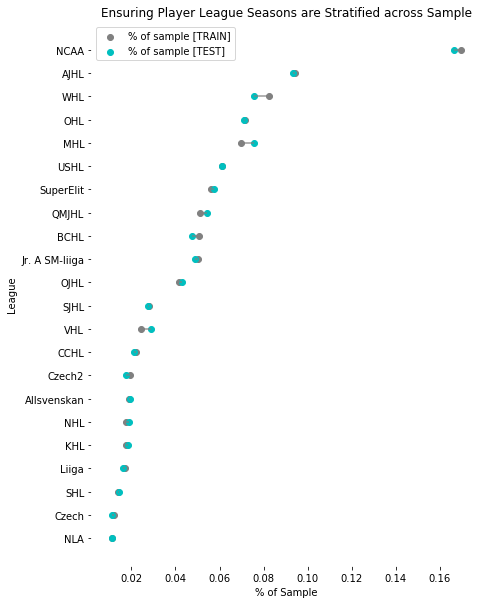
We begin with approximately 69,000 player seasons across 24 leagues between 2005-2019. That’s 26,516 player batches that will be fed into our LSTM RNN. We will be padding player careers so the season dimension of the player tensor will always be 7 in length. We’re going to split 70%/30% for training/test datasets, which gives us 18561 * 7 = 129,927 observations for training and 55,685 observations for our testing. One thing I noticed in the validation / EDA steps, that I want to mention before the modelling section, is the distribution of player seasons by league. The count of NCAA player seasons is rather high, representing >16% of the sample, which gave me pause. High NCAA representation meant a lot of non-zero predictions for NCAA in the following season even if that transition is seldom observed (i.e. Liiga -> NCAA is impossible).
With that being said, I wanted to ensure that train / test datasets were stratified by league so that league proportion was consistent between samples. It appears well stratified given the following:
Data pre-processing is one of the most important steps because that’s where we implement the assumptions we make about our data. Broadly, the steps taken are as followed:
- Read-in player and season data from eliteprospects
- Calculate age information at the season level
- Collapse player league season information1
- Split data into x, y datasets and Min-Max feature scale (also create a train/test split)
- Pad player seasons2
- Generate player Batches to feed through Network
After we’ve pre-processed our data, let’s take a peak at how the sequences are set up to feed into our neural network. We have a list of player padded seasons, that will have to reshape into a Tensor that’s shaped (player, season, features).
Model Training
Now that we’ve prepared our data to pass to our LSTM, it’s time to actually create our model object. Both Keras (a higher level API that sits on top of Tensorflow) and PyTorch are intuitive Python wrappers for deep learning frameworks. The choice to go with PyTorch came down to the flexibility of the API. This was my first implementation of an RNN so I gravitated towards a more Python-friendly use-case.
Implementing the model came down to a few steps:
- Create a model class that inherits the PyTorch module
- Initialize the model class with a few hyperparameters
- Initialize the activation functions needed
- Write a forward function for the model
The way I wrote the forward function is one of the reasons I chose PyTorch for this implementation, since I had more control over how the data would be passed through the network. For each player that’s fed forward, a new hidden and cell state need is initialized because you don’t want correlations / information between players to persist. We then loop over the 7 player seasons passing one season at a time to the LSTM with the hidden state that’s being updated after each season. I also added a second activation function in forward pass because it’s possible to return negative values after the linear projection, but we all know that player points-per-game cannot be less than 0. I keep track of which inputs were padded, and only return true predictions so the loss is only calculated on true observations. Once the model’s forward function is written, we can move on to training the model.
APPLE Architecture
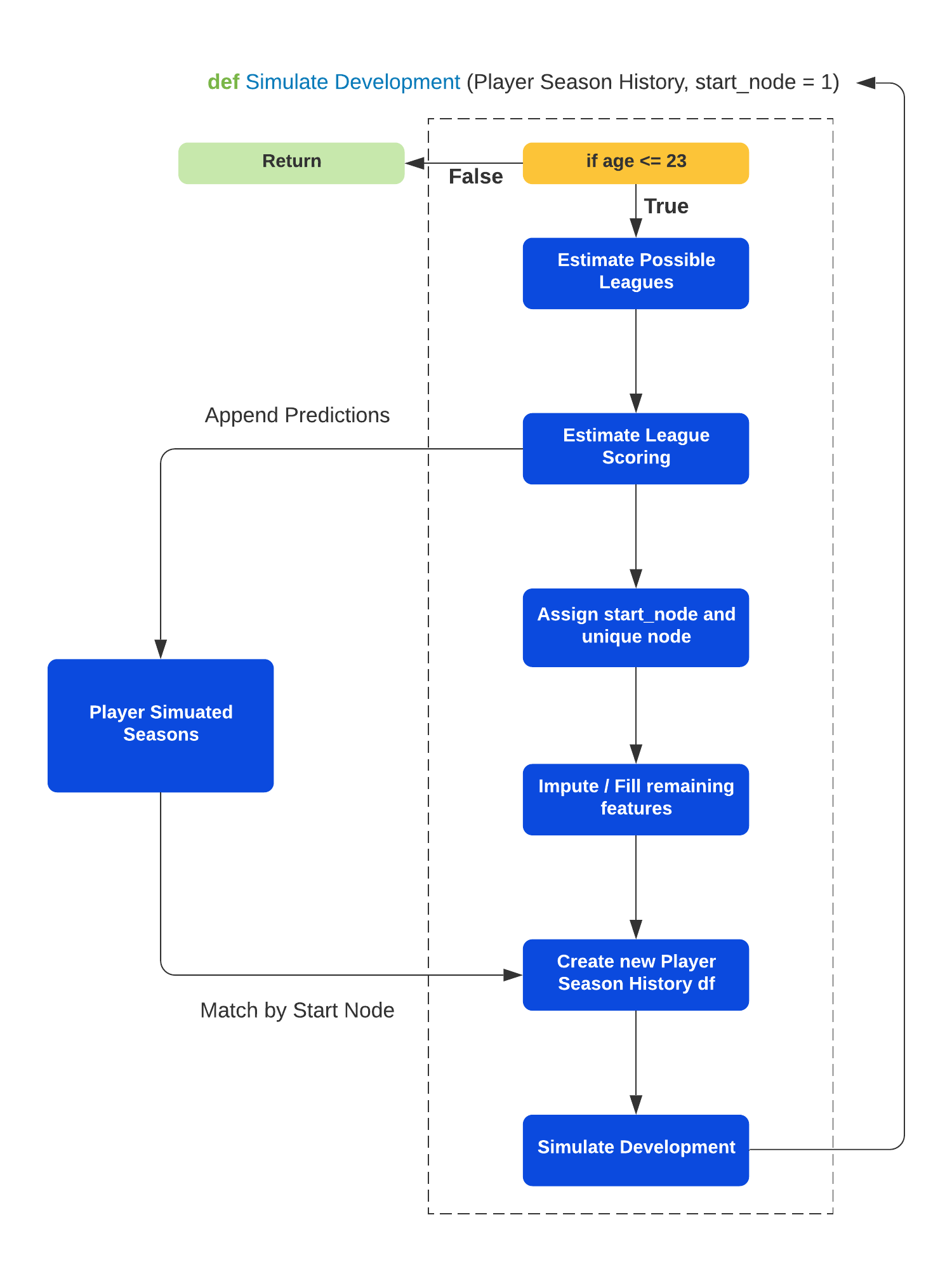
Now that we’ve trained our models, each will act as their own component of the higher level APPLE model. APPLE’s architecture follows an iterative / recusive structure, that can be traced using directed graph networks. Every simulated season is assigned a node in the network of nodes, and because of the “recursive” structure, each node only has one season directed to it.
We briefly talked about APPLE’s architecture in the methodology section. In pseudo-code, the following function simulates a player’s development until they reach the base case — the base case being they’ve aged out at 23. Intuitively, this creates independent timelines across nodes at each age, and that node is conditioned on just one other node. With that, we can essentially calculate the NHL likelihood at age 23 since all the logits sum to 1. This gives us our level of risk, and for the reward side of the equation we’re calculating the production a player would expect at each season. To get our Expected NHL Value, we sum the products of expected points and the conditional probability of all NHL node.
Results
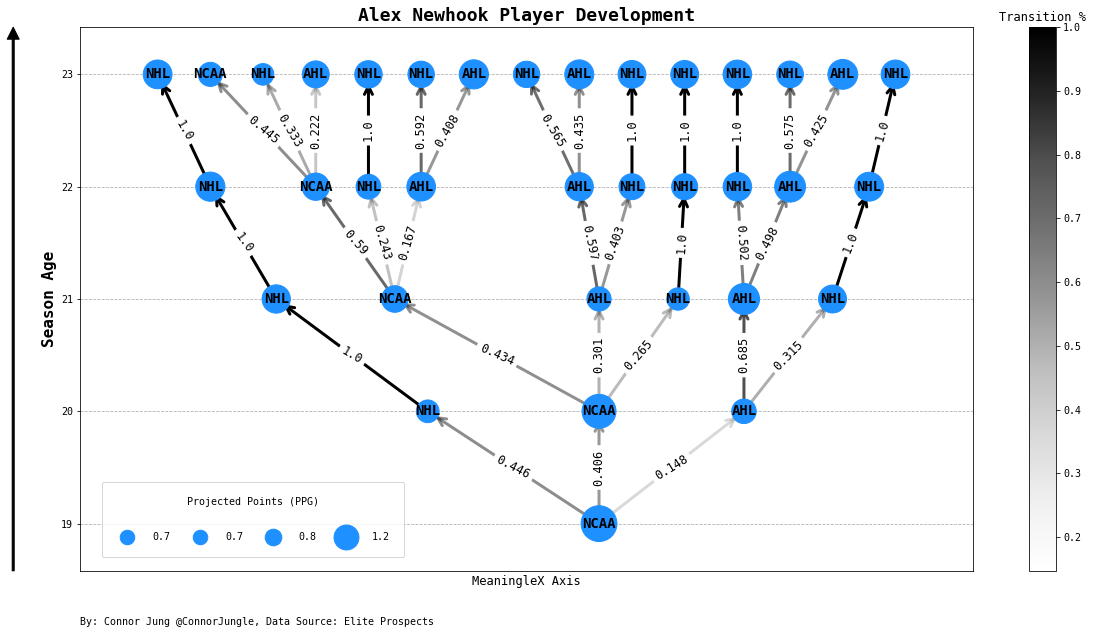
Let’s look at an example, Alex Newhook (one of my favorite prospects from last year’s draft) is a 19 year old prospect who just finished his Draft + 1 season in the NCAA. We pass this past season, plus his two BCHL seasons, into APPLE to simualte his 20 year old season. This produces three possible outcomes {NHL, AHL, NCAA} based on his scoring and other player features. We can then estimate his scoring conditioned on the three possible leagues, and the process repeats itself until he reaches his hypothetical 23 year old season.
The simulated seasons begin to unearth the potential development paths a player can take on their way to the NHL. With these simulated seasons, we can begin to ask some interesting questions about player developement:
- How likely is a player to make the NHL today?
- How much do we expect them to score in the NHL at age X?
- What is the expected value of a player over the first 5 year after being drafted?
- What is the development path that maximizes a player’s likelihood to play in the NHL?
- What is the development path that maximizes a player’s production in the NHL?
APPLE thinks Alex Newhook has an 87% chance to make the NHL by 23. At that strong a likelihood to play in the NHL, his expected NHL Value over in the 5 seasons since being drafted is ~135.7 points.
Another prospect I was high on at last year’s NHL Draft was Arthur Kaliyev. While many argued that his footspeed and general competitiveness were major flaws in his game, it’s hard to argue with his production in the OHL the last 3 years. If we look at Arthur Kaliyev’s APPLE developement path, we can see what paths will either maximize his likelihood to play in the NHL or his production in the NHL.

Kaliyev’s development paths highlight an interesting piece of player development that NHL team’s have to balance with prospects — where to play prospects before the NHL. Without a comprehensive academy style feeder systems (like in European football), NHL teams have to carefully consider where to play prospects before they’re ready to graduate to the NHL. Not all prospects get the same opportunity, where draft pedigree is a known bias3 , so it’s important to properly stagger prospects and time prospect graduations. By estimating a player’s most likely NHL path, we can attempt to put players in the right roles/leagues to maximize the likelihood they play NHL games. On the other hand, if you have a high risk / high reward prospect and are willing to “rush” them to the NHL, you may reap the benefits because once you’ve established you’re an NHL player, the league model will continue to think you’re an NHL player the following year. Specifically for Kaliyev, his Most Likely Development Path has him making the NHL at 22 years old (~28%), where he’ll amass ~152 points after spending his 20 year season in the OHL again, and one year of seasoning in the AHL. However, if LA wanted to Maximize his NHL Value impact, he could make the jump to the NHL next year at a lower probability (~13%), but potentially score ~313 points over the first 5 years.
Team Prospect Pipelines
Another application of APPLE is to evaluate Team Prospect Pipelines by using the NHL Expected Value metric for each prospect. The old addage of “stocking the prospect cupboard” takes on a whole new meaning.
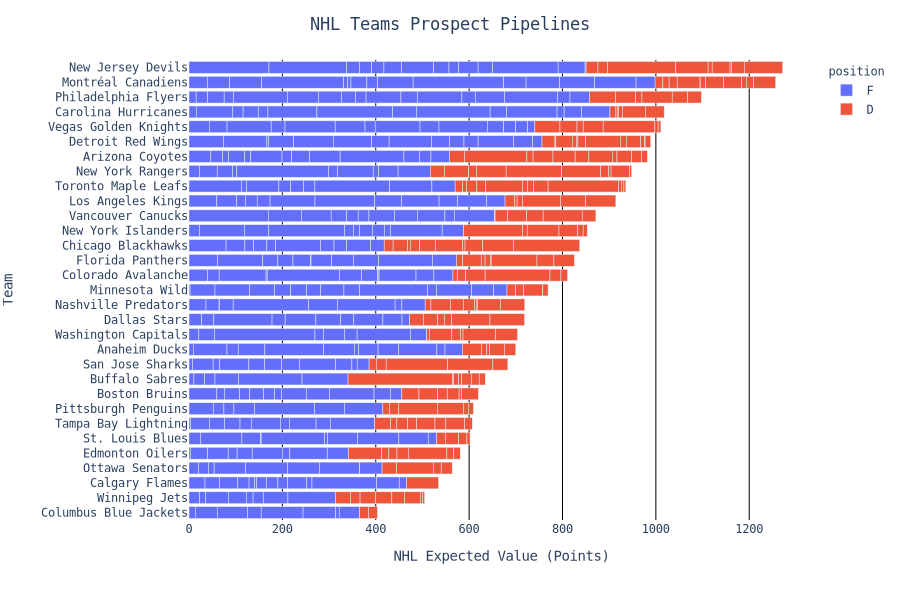
Unsurprisingly, the New Jersey Devils come out at the top this list — having received the 1st overall pick in 2017 and 2019. While it’s a little disingenuous to consider Nico Hischier or Jack Hughes to be “prospects”, it’s a fun exercise to see which teams possess a wealth of young talent. The Montreal Canadiens are also high on this list with a different approach, which essentially comes down to quantity over quality because they’ve selected 21 players in the last two NHL Drafts. One team that was surprisingly high was the Philadelphia Flyers, who appear to have done really well value-wise in the 1st and 2nd round the last few years. Notable stand-outs were Bobby Brink, Morgan Frost, Joel Farabee and Cam York.
It’s important to note that NHL Expected Value is only measured by goals, assists and points, because we lack the granularity to look at metrics that are more predictive of success. One shortcoming here would be drastically undervaluing defensive specialists that do a great job suppressing shots and scoring chances. While this is a shortcoming of the model, even defensive specialists have to score enough to be a net-positive to graduate through the leagues necessary to have an NHL bid so the methodology of this model still holds.
Model Evaluation
League prediction model
I decided to go with the baseline xgboost model for predicting what league a player is likely to play in year y+1. The LSTM architecture quickly overfit the data and became very confident in its predictions even with 23 possible leagues. The LSTM accuracy was quite good, but the model was so confident in its classification that the log-loss was much higher than the baseline out-of-sample.
Since I was more interested in the possible outcomes of leagues, the baseline xgboost multi-class model produced more general/reasonable outputs. With incredible work done by Scott Lundberg, we can now visualize boosted tree models to see what happening under the hood.
Let’s take a look at what’s most important in predicting a player will play in the NHL in y+1:
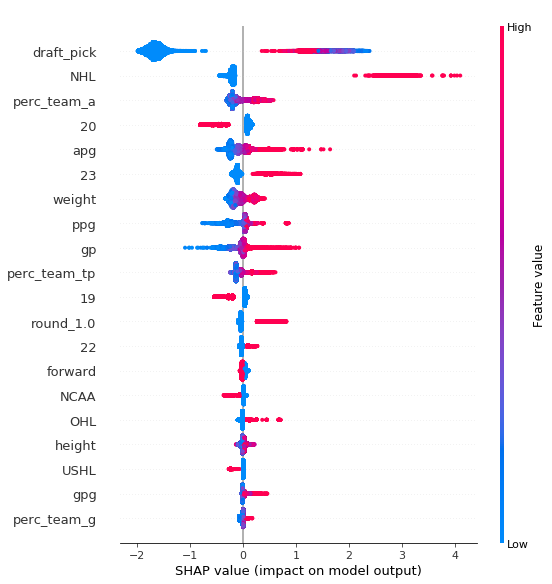
The feature importance plot of the league prediction model is interesting. Not only can we see which features are most leveraged in the trees, but we can also see how its distribution affects the output (positively/negatively). What stands out:
- There are some non-linearilies in
draft_pick - The older you are, the more likely you’re to play in the NHL next year
- The importance of
perc_team_awhich attempts to capture which players bare a higher responsibility of assists (scoring in general) for their team
| Model | Accuracy | Log Loss |
|---|---|---|
| LSTM | 86% | 0.53 |
| xgboost | 84% | 0.57 |
| Training Set |
| Model | Accuracy | Log Loss |
|---|---|---|
| LSTM | 80% | 1.6 |
| xgboost | 84% | 0.58 |
| Test Set |
Scoring Prediction Model
| Model | MSE | R^2 |
|---|---|---|
| LSTM | 0.03 | 0.70 |
| xgboost | 0.05 | 0.54 |
| Training Set |
| Model | MSE | R^2 |
|---|---|---|
| LSTM | 0.06 | 0.48 |
| xgboost | 0.05 | 0.54 |
| Test Set |
Model Fit
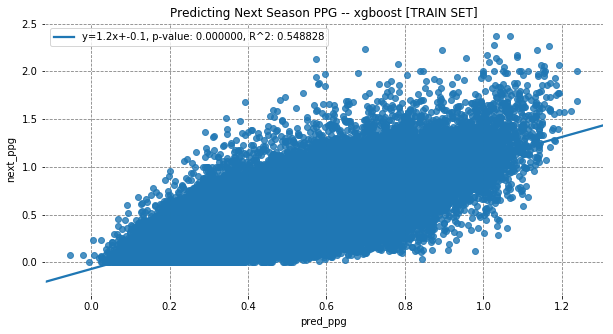

The RNN LSTM outperforms the baseline xgboost by quite a large margin in R^2 and MSE in training.
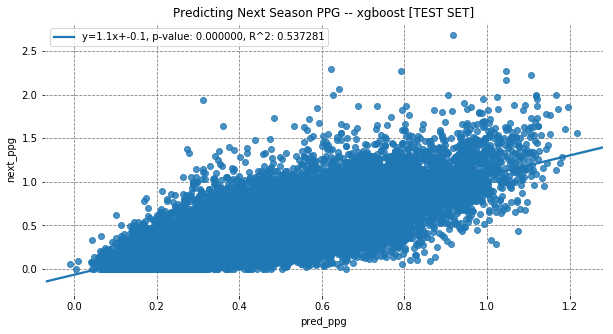

Baseline xgboost performs slightly better than RNN LSTM in test set results using R^2 and MSE.
Distribution of Predicted Values


Given that out-of-sample results were worse for the RNN LSTM in terms of R^2 and MSE, we can’t definitively conclude that it outperforms xgboost, but I’m comfortable with the RNN LSTM’s results given that the distribution of outputs do fit ground truth more generally than the baseline.
Limitations
At the onset, we stated that APPLE is trying to quantify Risk and Reward conditioned on a player’s time-dependent performance. There is a fear of over-engineering the task at hand. Model complexity needs to be top of mind for any analyst, because the trade-off between bias and variance affects how we interpret our results.
First, let’s talk about model fit. Typically, it’s hard to decisively beat xgboost in regression problems based on my experience with hockey data (I’d also point to the many Kaggle competition winners since 2017). Comparing the baseline xgboost and LSTM when predicting scoring performance in y+1, the training set improvement in MSE and R^2 are conclusive. However, when we evaluate the models on the test set, the baseline xgboost tends to do better in these metrics. Interestingly, if we look at the distribution of predicted values, the LSTM does tend to fit the grouth truth a lot better. It appears that the LSTM model has higher variance error than the baseline, given the difference in MSE between train / test sets — characteristics that the model is overfitting. Perhaps LSTM isn’t a decsive improvement over xgboost, and other model architectures (ie. Transformers, CNN, etc.) may be better suited for the problem.
Second, there is no measure of uncertainty in APPLE’s performance projections. If Alex Newhook plays his 20 year old season in the NHL, the model predicts 0.5 PPG (points per game) but we lack any confidence interval or range of possible performance. This is important because performance projections become inputs to future predictions, meaning outliers can heavily influence predictions downstream.
Third, training neural networks can take a lot of time, resources and proper optimization frameworks. This implementation focused more on developing a model that 1) learns something, 2) outperforms benchmark, and 3) produces reasonable outputs. There are probably marginal improvements on both the baseline xgboosts models and LSTM models if we threw more computing resources, time at the problem and used training optimization techniques. For example, while it’s standard to use the ADAM optimizer — which keeps an exponentially decaying average of past gradients — I did not include any dropout or regularization, and I did not implement early stopping. These are all elements that should increase model performance, make predictions more robust, and be less prone to overfitting.
Last, RNNs typically use model output as inputs for the next time-step in training. When predicting player development, we have no choice but to use model outputs as inputs in hypothetical seasons; however, we use ground truth performance at each time-step in training. This is a concept called Teacher Forcing, and will lead to better results since we’re using ground truth in training as opposed to using the model outputs as inputs. A balanced approach leveraging both Teacher Forcing and Model Outputs in training can provide the best of both worlds. For example, we could choose to use ground truth 50% of the time, and use model outputs the other 50%.
Closing Thoughts
The goal for APPLE was to build a better solution for the old problem of player development. It draws heavily on core principles of its predecessors, while applying modern deep learning techniques to give APPLE a novel feel. There is a balance that has to be struck when setting your sights on new model applications because the fear of over engineering the problem is high. To combat the common tropes of deep learning frameworks, I want to address the limitations of APPLE in future iterations by perhaps implementing some bootstrapping methods, regularization and early stopping.
The application for this model is quite widespread: pre-draft rankings, analyzing team prospect pipelines, and fantasy. The NHL draft has been one of my passions since attending the ‘06 draft in Vancouver as a kid, and was undoubtedly hooked when I discovered hockeydb.com and its sorting feature on each draft class. Hopefully this model adds to the fury of draft coverage, discussion and excitement as we move closer to the 2020 draft.
I’ve started working on creating a beta web-application to host the model outputs, and would love feedback on the model, the data visualization and any questions/concerns people may have.
Footnotes
1. Aggregate player seasons intra-league (Sum) -> Aggregate player season intra-season (Max GP)
2. Padding is a pre-processing technique for Neural Networks, specific to handling different sized sequences as we have with player careers. This helps the model train when sequences are all the same length
3. Sunk Costs in the NBA: Why Draft Order Affects Playing Time and Survival in Professional Basketball (1995): https://www.jstor.org/stable/2393794?seq=1

A couple of questions:
1: Why did you reject the 200 NHL GP? A model I’m working on model where the threshold is 100GP for a replacement level player, considering that would be the kind of games played for a healthy scratch over the years from their ELC to when they would be eligible for arbitration(also it’s basically an extension of expansion draft rules.)
2: Why only go back to 2005? There’s good data gong back to the 2000 draft for height & weight. with 2000, you have a lot more full careers to model off of.
3: What kind of player breaks your model? Somebody like Elias Petterson breaks mine because he’s so slight for his height he shouldn’t be an effective player.
Hi Alec,
Thanks for the comment.
1) I don’t necessarily reject the 200 GP threshold, it’s simply an approximation for what an “NHL Player” is. I wanted to frame the problem differently because previous models would take any season — wether a player was 18, 19, 20, …, and make a prediction if they’ll play 200 games without accounting for any information in between. It’s also counting 200 games as career total, and a lot can happen in a player career. It was a personal choice, and it came down to me having a hard time being confident in a model that projects that far out, fit on a target variable that’s very disassociated with the feature set.
2) More data is better — most of the time. The problem is that when you span that many years you can code era-bias that may not be captured in the model. For example, in the dead-puck era, perhaps scoring was less important in prospect graduation from junior to pro, and draft status was a lot more important to managers in where player’s played. Where as nowadays, it’s hard to justify not giving a high scoring player a chance to move up and around leauges.
3) The model actually handles elite players really well, so extraordinary players like McDavid, MacKinnon and other project out to be impact NHL players. I was worried it wouldn’t handle top 5 NHL drafted player’s well as there is obviously an exponential decay of player ability in the draft order (2nd overall is half as good as 1st, and so on). What the model struggles with, and it’s what I wrote in the write up, are players with outlier seasons. A player recently that’s done that is Arizona Prospect Jan Jenik, who scored over 2 PPG this year, and the model compounds and thinks he’s going to be an all-star caliber player when it should be a little less certain of that.
Connor
You might want to look at the work of Schuckers (2016), Seppa et al (2017) and work by Nandakumar