
Listen; I get it. Some people are sick and tired of this supposed debate that’s been ongoing for over ten years now. But what really is the actual debate all about? What is it we are arguing on Twitter over? What should we be aware of?
Prior to diving into the debate and showing some numbers, let’s define what we mean when we say “shot quality”.
Shot quality in its simplest form is a combination of all the factors involved in an individual shot that changes the likelihood a goal is to occur relative to another shot, with a caveat of ignoring goaltending talent differences. In a more mathematical sense, shot quality is the expected shooting percentage of a shot if we were somehow able to create a perfect and all encompassing model.
There are a lot of elements involved within shot quality. There are measurable known factors, like that DTMAH’s expected goal model uses: shot distance, shot angle, shot type, rush shots, rebounds, handedness of the shooter, and the shooter’s heavily-regressed historical shooting percentage. There are also measurable factors not yet available in significant quantities, like what we’ve been finding with the passing project.
Of course, there are also all the unknown factors, the not yet discovered and that which may never be fully understood.
With each additional component we can account for, the returns for the next unknown component diminishes. Why is that? For the most part, the skills and inputs that make a player effective are translatable to other areas. While exceptions obviously exist, we see this in many areas like with the relationship between player Corsi% and point production. Many of the players who improve shot quality due to many of the earlier described factors likely also perform well in many of the components not yet accounted for or discovered.
Exceptions will always exist, though, which is why it is important that we never stay content with what we know and learn more about the game. Models that look at components of shot quality like expected goal models do not cover everything, but they are a step in the right direction.
With each new discovery we push out the boundaries of what we know and move our models to higher and higher predictive strength:
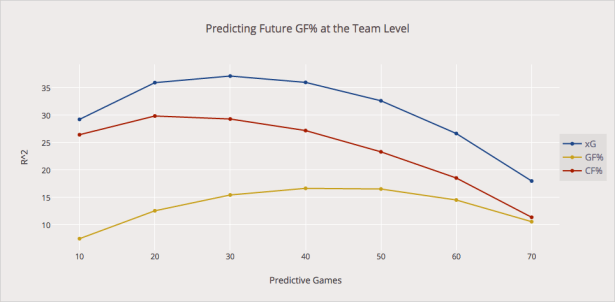
Graphic from Asmae and DTMAH’s article on expected goals.
So far, we’ve discussed shot quality predominately from the offensive team’s perspective; there is a defensive side to the equation as well. While the team with possession tries to maximize the probability of a goal being scored from each shot, the defensive side battles to minimize it.
Defensive coaching axioms centre around countering many of the shot quality factors we already mentioned:
- Keep the pucks to the outside
- Prevent odd-man rushes
- Take the pass, to avoid cross-ice goaltender lateral movement and backdoor passes
- Pick up rebounds and box out any players in front of the net
- etc.
Just as the scoring teams trying to maximize shot quality factors are trying to increase expected shooting percentage, the defensive team is trying to minimize these factors and lower the expected shooting percentage, in other words: raise expected save percentage.
The next step would be then to look for players that impact save percentage… but when we did start looking at this we found something surprising. We found an extremely low auto-correlation and slope when relating past to future save percentage impact:
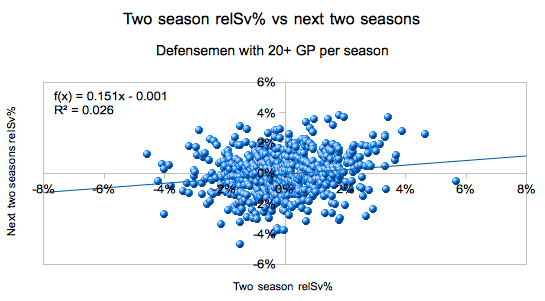
This type of analysis matters. It’s not enough for a friend to simply pull off a trick shot when playing a game of hoops together; you will likely taunt them with “bet you can’t do that again.” Why? Because the ability to something desired being a skill rather than chance is related to the ability to repeatedly accomplish that task.
I wanted to make an example of this by investigating a bunch of players who are considered to have a legitimate impact on team save percentage. Fortunately, I stumbled upon an article by David Johnson that did all the work putting together a list for me.
In the article, Johnson presents 25 forwards who impact save percentage positively, and then 25 forwards who impact save percentage negatively. He then repeats the process for defensemen, given a sample size of 100 players overall.
I then went to look at how these players performed in relative-to-teammate save percentage for all seasons since that article was written. I realized halfway that Johnson provided a second list using another method (trying to take into account Quality of Competition) in an addendum at the bottom of the article.
Note: I ended up just looking at just forwards for Johnson’s first method and then the defenders for his second method. I was fine stopping here given the results were similar in both cases and that there is a large overlap in players in both lists. However, to prevent anyone from feeling like I’m cherry picking the data, feel free to look at defenders in the first list but not the second, forwards in the second list but not the first, and provide your results in the comments below. I’ll include an addendum to this article on whether or not the results change.

We find that 35% of the players considered to have a particular impact continued to have the same direction of impact, while 46% of players did not. Removing the 19 players that did not play in the future sample, we see that only 43% of the players Johnson listed ended up actually having the same direction of impact in the future as they did in the past.
If relative save percentage was completely random, we would expect around a 50/50 split. Now, these results do not say that relative save percentage is completely random. What it does suggest is that the observed results do not act any different than what we would expect if they were random.
We should remember though that the results we observe exist in the environment they originate from.
For one example, all NHL teams try to play defensively sound games and follow the defensive axioms like the ones listed above. If this were suddenly not true, the observed relationship could change. If suddenly a large number of players or teams stopped caring or trying, we might not see what we have here.
Another example of potential environment context is the distribution of talent. If defensive skill in shot quality varies from player to player much less than offensive skill, we could see a dramatic change in results if the opposite were true.
What is the take home message then? How should management, coaches, and analysts act given this information?
Well, when you look at a player who has a particular impact on relative team save percentage, you cannot simply assume that means they are effectively causing that impact and will continue to perform like that. You will first need to heavily regress the data and assume their impact is being heavily exaggerated (example: for a two-season sample on a defenseman, you would regress by 85%, or assume they are only 15% as good as you observe). Then, you would need to remind yourself that just the direction of that regressed value is likely only right 50% of the time.
Or you could just use this “will their positive or negative impact on save percentage persist” tool.

Hey interesting article!
Can you take a look at Derek Stepan for me? Each season for the last 5 seasons (current one included) his 5v5 save % is considerably higher than his off ice save %. It has always struck me as running against the “players can’t influence on-ice save %” orthodox. I’ve looked at numbers for a lot of other NHLers and I can’t find anyone who outperforms their off-ice save% as much or as consistently as Stepan does. Very interested to hear a statistician’s take on it.
Thanks for this and for everything you do!
The point of this article is that when we have individuals who garner particular results, it’s extremely difficult to separate where it is a skill, even when they are consistent over many years. Because, if it were just pure randomness, we would expect some to have consistently good/bad results because randomness is not evenly distributed.
Now that said, as I noted there are particular inputs within shot quality. Stepan consistently does better in things like expected goals against than shot metrics like Corsi or Fenwick. Because of this, I would suggest then that at least part of his success in relSv% is from his ability to reduce shot quality, although with the caveat that it’s difficult to know how much at this point.
Are there other variables that come into play- such as: declining age, type of team structure, coach, and the trap?
I would venture to guess yes, but these would definitely skew the semantics.
Don’t guess! You can do the work, and share it with us! I’d be curious to see how you’d demonstrate that a neutral zone system like the trap influences shot quality in an offensive zone, for instance. I also think changing shot quality as a person ages could be a very interesting study! In other words, if you want to put forward something as evidence of a counter-narrative…show evidence! We (and everybody else) would be interested to see it!