
The usefulness of on-ice save percentage (and derivative metrics such as Sv% Rel and Sv% RelTM) has been the source of many, many heated debates in the analytics blogosphere. While many analysts point to the lack of year-over-year repeatability that these metrics tend to show (past performance doesn’t predict future performance very well) as evidence of their limitations, others (primarily David Johnson of HockeyAnalysis.com) have argued that there are structural factors that haven’t been accounted for in past analyses that artificially deflate the year-to-year correlations that we see.
David’s point is a fair one – a lot can change about how a player is used between two samples, it’s not unreasonable to think that those changes could impact the results a player records. But we don’t just have to speculate about the impact those factors have – we can test the impact, by building a model that includes measures of how these factors have changed and seeing how it changes our predictions.
In order to assess David’s claim, I asked him which variables he felt had an impact on save percentage metrics that could potentially be reducing the simple correlations that we observe. Here were his responses:
https://twitter.com/hockeyanalysis/status/764178935559163905
https://twitter.com/hockeyanalysis/status/764180715600801792
https://twitter.com/hockeyanalysis/status/764181469543759872
To play things on the safe side, I decided to check whether future results for any of the 3 on-ice save percentage variables (Sv%, Sv% Rel, and Sv% RelTM) could be predicted using past results of any of the 3 on-ice save percentage variables. I also split the data by position to see whether forwards and defencemen had a different impact on whether their goalie stopped the puck.
I ended up running 18 linear regressions (3 future variables to predict * 3 predictor variables * 2 positions). In each regression the dependent variable was a player’s 2012-2016 results for the variable in the “Predicting Column” (one of the 3 Save Percentage metrics listed above from 2012-2016). The predictors I used were a player’s results from 2008-2012 for the variable in the “Using Variable” column (the player’s past Save Percentage metrics from 2008-2012), as well as the change in the following variables between 2012-2016 and 2008-2012:
-TMGA60
-OppGF60
-DZ FO%
These change variables should capture the impact of changes in Quality of Teammates (defensively), Quality of Opponents (offensively), and Usage/Role, respectively.
Data was taken from puckalytics.com. All players with more than 500 minutes in each period were included.
For each regression I’ve presented 3 results:
-The Adjusted R^2 – how well the overall model predicts the variable it’s trying to predict
-The Regression Co-Efficient for the variable in the “Using Variable” column
-The P-Value for the variable in the “Using Variable” column
Models where the P-Value of the variable in the “Using Variable” column is less than 0.05 have been highlighted in green.
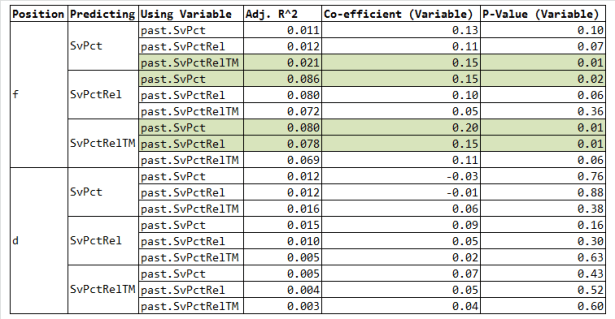
As you can see, the Adjusted R^2 for all of the models never gets above 0.086, indicating that even in the best case we’re only explaining less than 10% of the variability in our metrics using a player’s past results and any contextual changes that occur. What this means is that although there are a few models where past results are a statistically significant predictor, there is a whole lot of randomness even in 4 years of save percentage data. The implication of this is that we need to be extremely careful when we use save percentage related statistics to describe the defensive play of skaters. We simply can’t say with a high degree of confidence that the players who have posted the best on-ice save percentage (or SvPct RelTM or SvPct Rel) in the past will be the players who post the best on-ice save percentage (or SvPctRelTM or SvPct Rel) in the future.
None of this is to say that players don’t have any impact on the likelihood that a given shot will go in. Personally, I do believe that players can have in impact on save percentage, however, the problem is that the impact is relatively small compared to the natural randomness in the samples we observe, so the data that we capture isn’t a good reflection of what that ability is. Even if we can know exactly what situation we’re going to put a player into, predicting how their save percentage is going to come out is a rather futile exercise – their past save percentage just doesn’t give much information to go off of.
